Efficient Multi-Threading
Performance is always important for users of The Server Framework and I often spend time profiling the code and thinking about ways to improve performance. Hardware has changed considerably since I first designed The Server Framework back in 2001 and some things that worked well enough back then are now serious impediments to further performance gains. That’s not to say that the performance of The Server Framework today is bad, it’s not, it’s just that in some situations and on some hardware it could be even better.
One of the things that I changed last year was how we dispatch operations on a connection. Before the changes multiple I/O threads could block each other whilst operations were dispatched for a single connection. This was unnecessary and could reduce the throughput on all connections when one connection had several operation completions pending. I fixed this by adding a per-connection operation queue and ensuring that only one I/O thread at a time was ever processing operations for a given connection; other I/O threads would simply add operations for that connection to its operation queue and only process them if no other thread was already processing for that connection.
Whilst those changes deal with serialising multiple concurrent I/O completion events on a connection there’s still the potential for multiple threads accessing a given connection’s state if non-I/O threads are issuing read and write operations on the connection. Not all connections need to worry about the interaction of a read request and a completion from a previous request, but things like SSL engines may care. We have several areas in The Server Framework, and more in complex server’s built on top of the framework, where it’s important that only a single operation is being processed at a time. Locks are currently used to ensure that only a single operation is processed at a time, but this blocks other threads. What’s more most of the code that cares about this also cares about calling out to user callback interfaces without holding locks. Holding locks when calling back into user code is an easy way to create unexpected lock inversions which can deadlock a system.
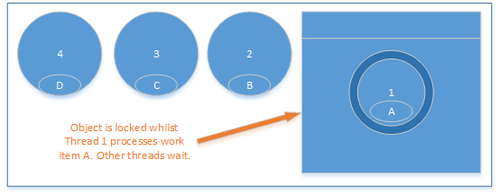
Threads waiting on a lock
In the diagram above, given the threads 1, 2, 3 & 4 with four work items A, B, C & D for a single object, the threads are serialised and block until each can process its own operation on the object. This is bad for performance, bad for contention and bad for locality of reference as the data object can be bounced back and forth between different CPU caches.
The code that I describe in the rest of this article forms the basis of a new “single threaded processor” object which enables efficient command queuing from multiple threads where commands are only ever processed on one thread at a time, minimal thread blocking occurs, no locks are held whilst processing and an object tends to stay on the same thread whilst there’s work to be done.
Reducing thread blocking
The amount of time that a thread needs to block on an object can be reduced by adding a per-object queue of operations to be performed. If we state that all operations must be placed into this queue before being processed and only one thread can ever own the right to remove and process operations then we have a design whereby a single thread will process an operation and any additional operations that occur whilst the thread is processing will be queued for processing by that same thread.
Obviously the per-object operation queue needs to be thread-safe and so we need to lock before accessing it. We also need a way to indicate that a thread has ownership of the queue for processing. The important thing is that the processing thread does not hold the queue lock whilst it is processing and so thread with operations for this object are only blocked by other thread with operations for this object whilst one of them is holding the lock to add its operation to the queue rather than for the duration of all operations that are ahead of it in the queue.
In the diagram below three operations for the object occur simultaneously and the first thread, thread 1, enters the lock, adds its operation to the queue and sees if any other threads are processing. During this time the other two threads must wait.
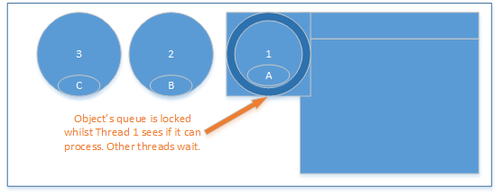
Limiting lock hold time
Once thread 1 is processing it releases the lock on the queue and enters the object to process the operation. Thread 2 can then obtain the lock on the queue and enters to add its operation to the queue and see if any other thread is processing.
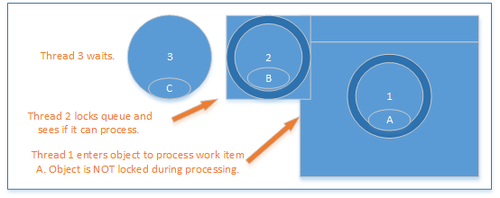
Lock not held during processing
Since thread 1 is processing, thread 2 simply enqueues its operation and returns to do other work. Thread 3 can then enter the lock that protects the queue.
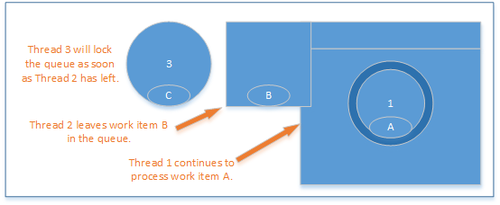
Efficiently enqueued operations
As thread 1 is still processing, thread 3 also simply enqueues its operation and returns.
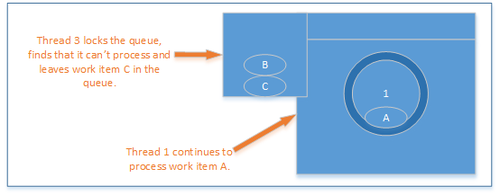
Thread 1 continues to process
When thread 1 has completed processing its operation it needs to give up the right to be the “processing thread”. To ensure that operations are processed efficiently it must first check the queue for more operations to process and process those before leaving the object to do other work. If another operation occurs whilst thread 1 is checking the queue then the thread with the operation, in this case thread 4, will block for a time.
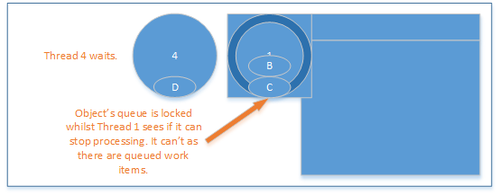
More operations are queued
Thread 4 can then enter the queue, check to see if it can process and if it can not then enqueue its operation for processing by the processing thread.
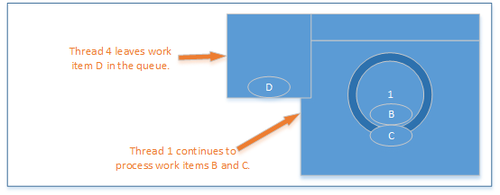
Thread 1 continues to process
Eventually the processing thread will reach a point where no further operations are queued for the object and it can surrender “processing mode” and return to do other work.

All the work is completed by thread 1
The key features of the system used above are as follows:
-
Operations can be enqueued quickly and efficiently so that the lock around the object’s operation queue is held for the least amount of time possible.
-
Only one thread can be “processing” at any given time.
-
The processing thread removes all queued operations when it checks the queue.
-
Locks are not held whilst processing occurs.
Of course once the above design was coded and integrated several other requirements emerged:
-
The processing thread must be able to enqueue a new operation.
-
Some operations require that they are processed before the thread that is to enqueue them is released to do other work as the other work may require that the operation on the object has already been processed.
The final requirement introduces some complication as threads that need to “process” an operation rather than simply “queue” an operation should block each other but not the threads that only need to “queue” operations. This requires a second lock and an event for the blocking threads to wait on. If a processing thread discovers other threads waiting to process it relinquishes processing and allows one of the waiting threads in to process. That thread processes its operation and then continues to process any queued operations in the usual way, unless, of course, there’s another thread waiting to process. This final use case is not needed that often if you design the code that uses these objects with the “queue and continue” design in mind from the beginning.
Implementation details
One of the key pieces of the design that I ended up with was the simplicity of the command queue. This is a memory buffer which can be expanded when it fills up. Each command is represented by a one byte value and a variable number of parameter bytes. The user of the queue is responsible for adding their commands and deblocking the commands once a thread is processing. To enable a swift switch from inserting data into the queue to processing the queued commands I have two queues; the active queue and the processing queue. When a thread makes the transition to processing mode it swaps the active queue for the processing queue and processes all of the commands in the processing queue. New commands are always queued to the active queue. There’s a lock around the active queue which must be acquired before you can manipulate the active queue and a separate lock to enter processing mode.
When attempting to leave processing mode a thread must first check the active queue for commands. If the active queue contains commands then it must swap the active queue for the, now empty, processing queue and continue processing. A thread can only leave processing mode when both the active and processing queues are empty. This in turn means that when there are lot of operations to be performed on a given object in a short period of time it’s usually a single thread that will end up doing all of the work.
An important consequence of the design is that the processing thread need not hold any lock whilst processing. Locks are only held when manipulating the command queue or entering and leaving processing mode. This simplifies command processing code as the processing thread can safely call into user-defined callbacks without risk of creating lock inversions.